This website allows you to search millions of records from around fifty datasets, relating to the lives of 90,000 convicts from the Old Bailey. Use our site to search individual convict life archives, explore and visualise data, and learn more about crime and criminal justice in the past.
In December 2019 this website was updated with the addition of two datasets on convict tattoos and a new search feature allowing you to search by convict occupations. A substantial number of additional punishment outcomes have been linked to trials. We have made a number of corrections to convict genders and ages, and new visualisations have been added to the visualisation gallery.
58,002 convicts in this database had tattoos. You can now search for specific tattoos and for specific types of tattoos on specific parts of the body. You can also create visualisations of tattoo design by body location, tattoo subjects according to religion, tattoo designs by place of birth and tattoo designs by occupation.

The majority of the convicts whose lives are documented in the Digital Panopticon spent some time on the hulks.
Hulks were decommissioned (and often unseaworthy) ships that were moored in rivers and estuaries and refitted to become floating prisons. Originating with the penal crisis caused by the outbreak of war with America in 1775, the hulks were intended as a temporary expedient for housing convict prisoners, but they remained in use for over eighty years. Find out more
See also

Several record sets included on this site contain details of the petitions submitted by offenders and/or their families and friends to the Home Office for the reduction or revocation of their sentences.
The Home Office usually, although not always, forwarded the petition and any supporting documents to the trial judge (or the Recorder of London, if it was a case from the capital), asking for a recommendation on the case.
Pardons provide some of the richest detail available on the lives of offenders. In putting forward the grounds for mercy, petitions often provide details of the offender’s life and circumstances at the time of the crime. Find out more
See also
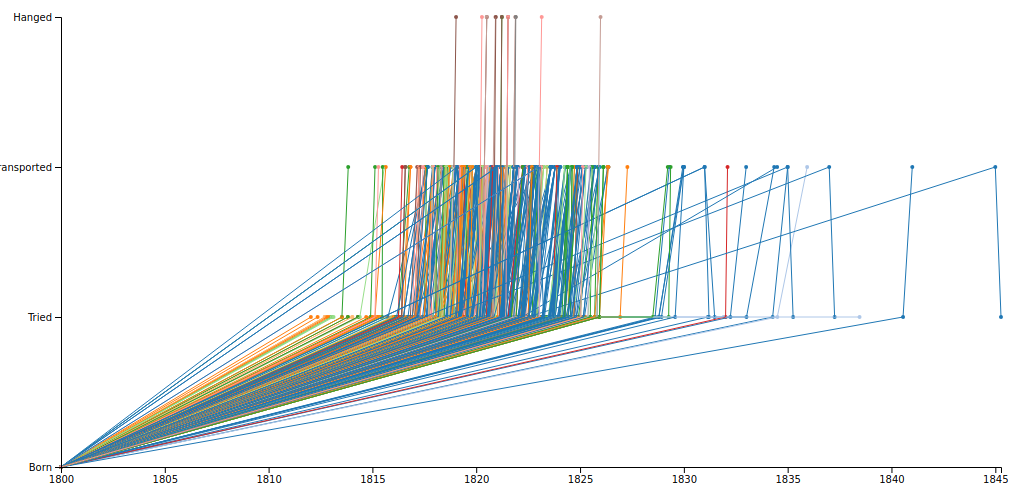
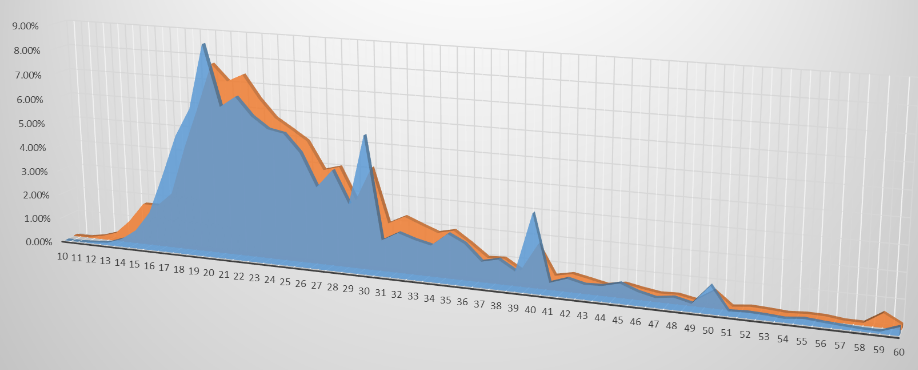
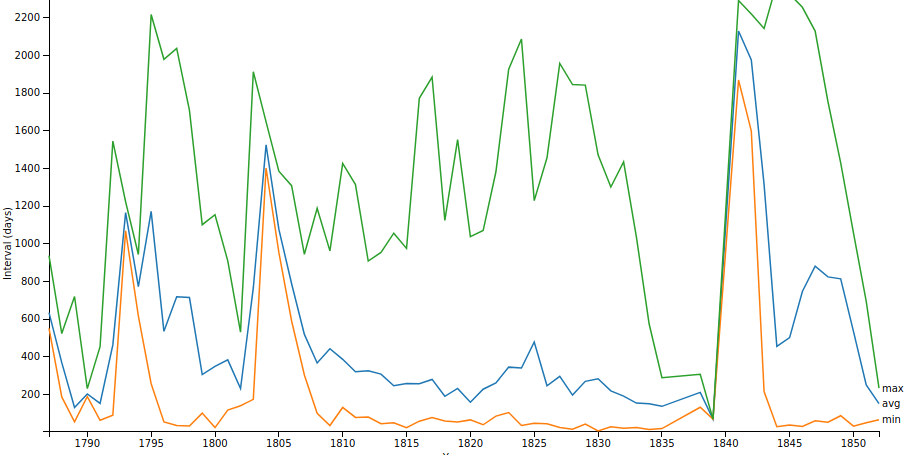
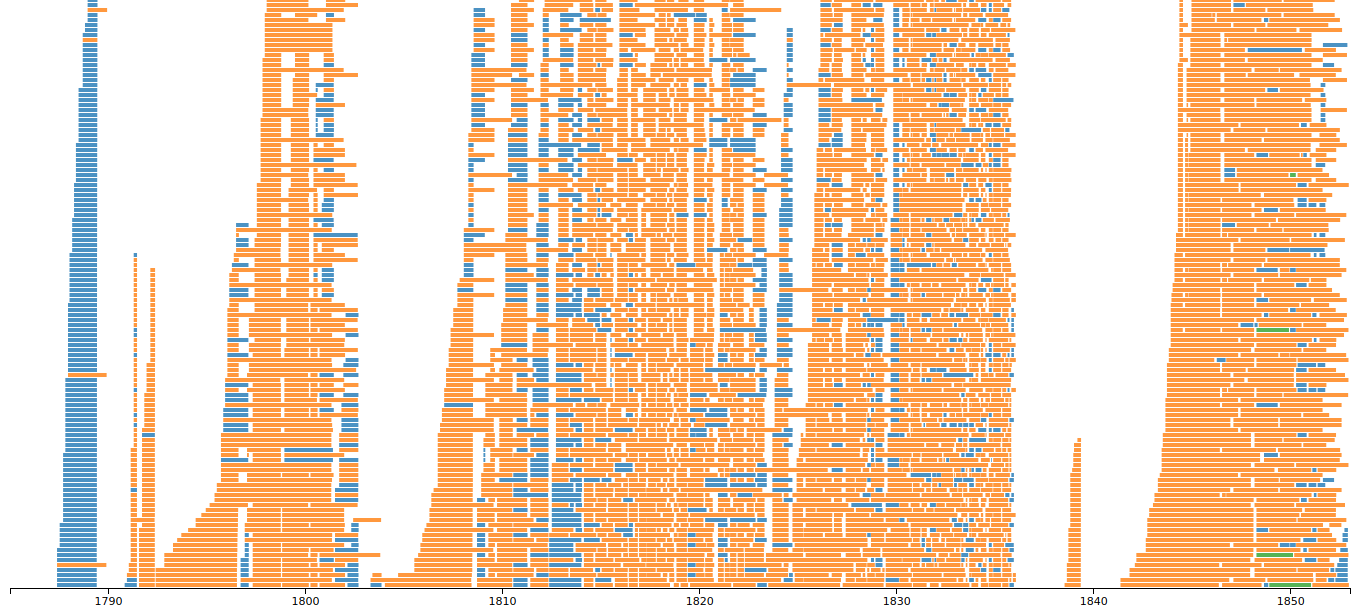
You can turn any Digital Panopticon search into a visualisation by clicking the Visualise link above the search results.
You can also browse our visualisation gallery.
You can search for people using details of criminal trials as well as name. You can even search using distinguishing features such as height or eye colour.
Every search you make can be customised using the 'Add more search criteria' button.

The Digital Panopticon is a Digital Transformations project funded by the Arts and Humanities Research Council.
A collaboration between the Universities of Liverpool, Oxford, Sheffield, Sussex and Tasmania, it is published by the Digital Humanities Institute.





