This website allows you to search millions of records from around fifty datasets, relating to the lives of 90,000 convicts from the Old Bailey. Use our site to search individual convict life archives, explore and visualise data, and learn more about crime and criminal justice in the past.
In December 2019 this website was updated with the addition of two datasets on convict tattoos and a new search feature allowing you to search by convict occupations. A substantial number of additional punishment outcomes have been linked to trials. We have made a number of corrections to convict genders and ages, and new visualisations have been added to the visualisation gallery.
58,002 convicts in this database had tattoos. You can now search for specific tattoos and for specific types of tattoos on specific parts of the body. You can also create visualisations of tattoo design by body location, tattoo subjects according to religion, tattoo designs by place of birth and tattoo designs by occupation.

The police played an important role in criminal justice throughout the eighteenth and twentieth centuries. Many trials at the Old Bailey were the result of actions taken by policing agents and involved them giving testimony and sometimes acting as the prosecutor. Systems of policing were under a process of continual reform, particularly in the nineteenth century.
In the eighteenth century, many victims of crime identified and apprehended the culprits before they contacted a formal policing agent to secure the arrest. While victims of crime continued to identify and prosecute offenders late into the nineteenth century, individual responsibility for law enforcement declined in this period. Instead, increasing numbers of men were paid to carry out these tasks. London was policed by a variety of parish constables, watchmen, patrols, and officers attached to magistrates’ courts. These different "policing agents" had separate, but often overlapping, jurisdictions and roles. Find out more
See also

These records contain details of some 1,127 pardoning reports and letters written by the Recorder of London and other trial judges on individuals convicted at the Old Bailey between 1784 and 1827.
Unlike the rather closed practices of the judges’ circuit letters and the Recorder’s Report, which have left little historical record, the Home Office judges’ reports provide a wealth of information on offenders and pardoning decision-making in later eighteenth- and nineteenth-century London. The judges’ reports were nonetheless still “hidden” transcripts, written in private between powerful people who did not expect the convict to ever see the documents. In this way, the judges’ reports differ from the petitions made by, or on behalf of, the offender; public transcripts that were written by the powerless to the powerful which deliberately sought to shine the light of public scrutiny on the authorities’ decision-making. Find out more
See also
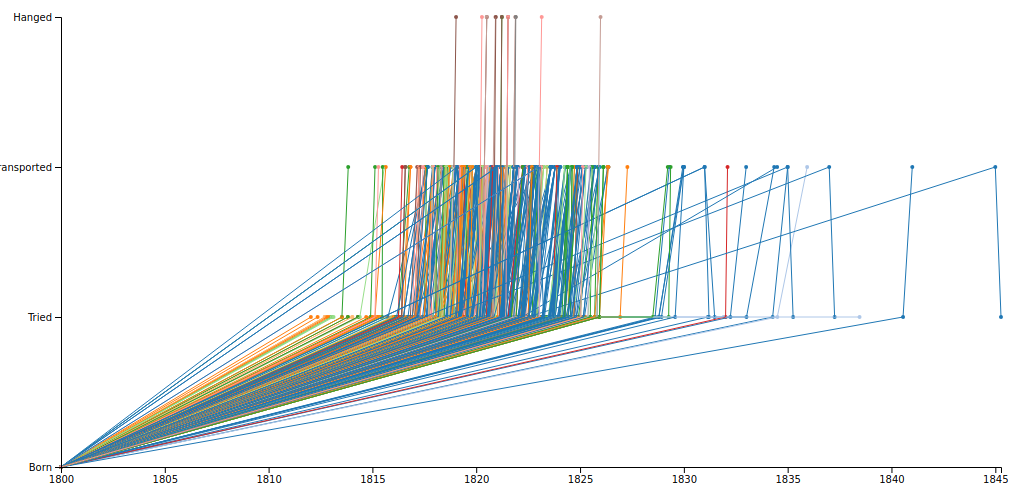
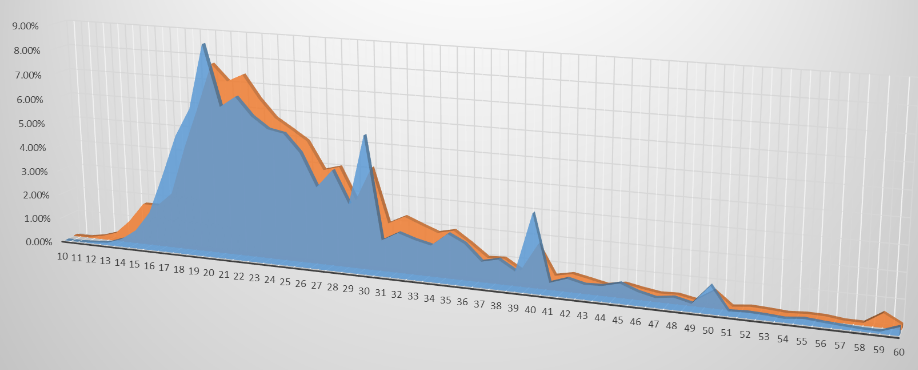
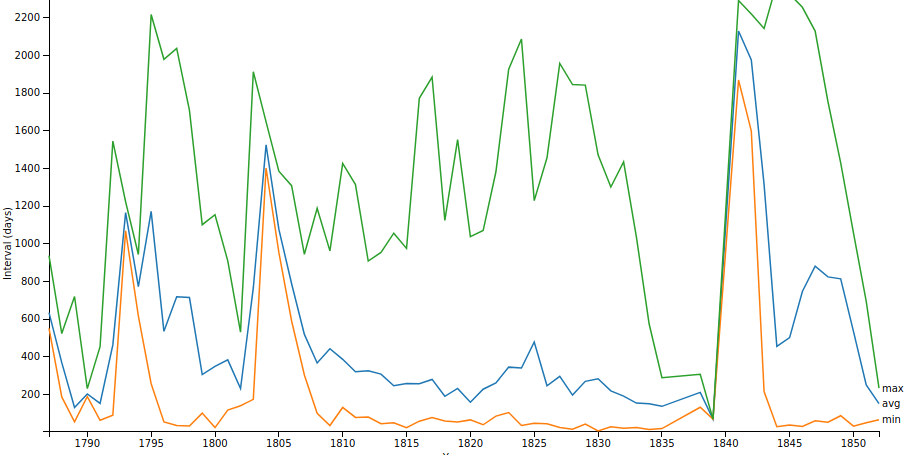
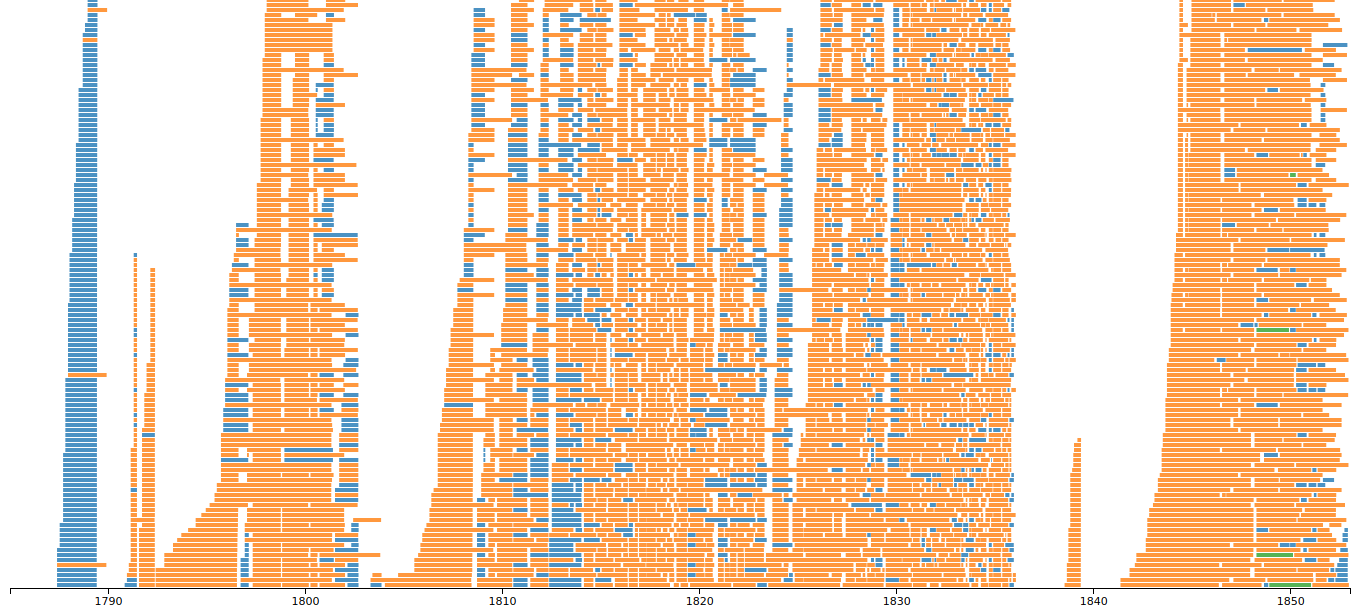
You can turn any Digital Panopticon search into a visualisation by clicking the Visualise link above the search results.
You can also browse our visualisation gallery.
You can search for people using details of criminal trials as well as name. You can even search using distinguishing features such as height or eye colour.
Every search you make can be customised using the 'Add more search criteria' button.

The Digital Panopticon is a Digital Transformations project funded by the Arts and Humanities Research Council.
A collaboration between the Universities of Liverpool, Oxford, Sheffield, Sussex and Tasmania, it is published by the Digital Humanities Institute.





